Completing the life cycle of digital photos by image dumping digital assemblages generated from detritus scraped from the world’s largest cultural trash can: the Internet. The AI generated images that I am drawn to exist between the horrific and the uncanny, and follow in the tradition of found vernacular photography.













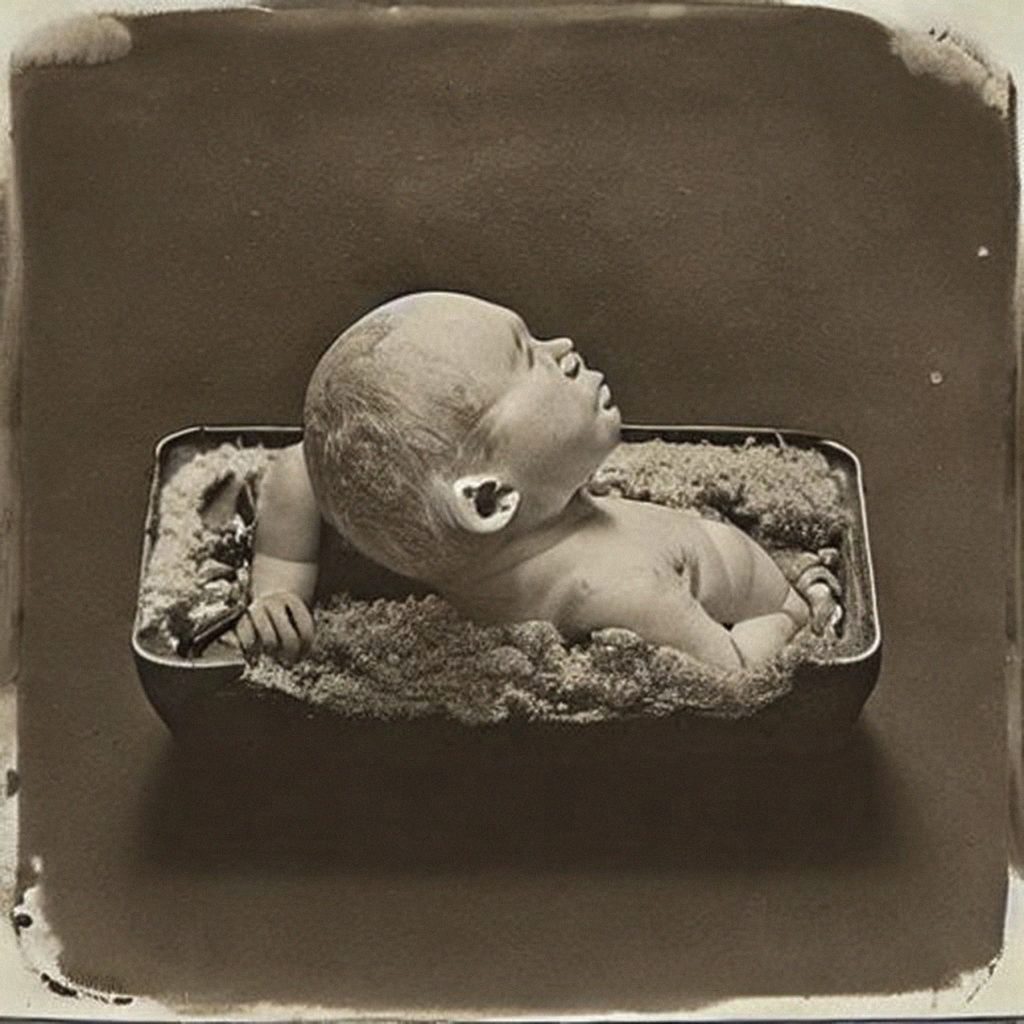



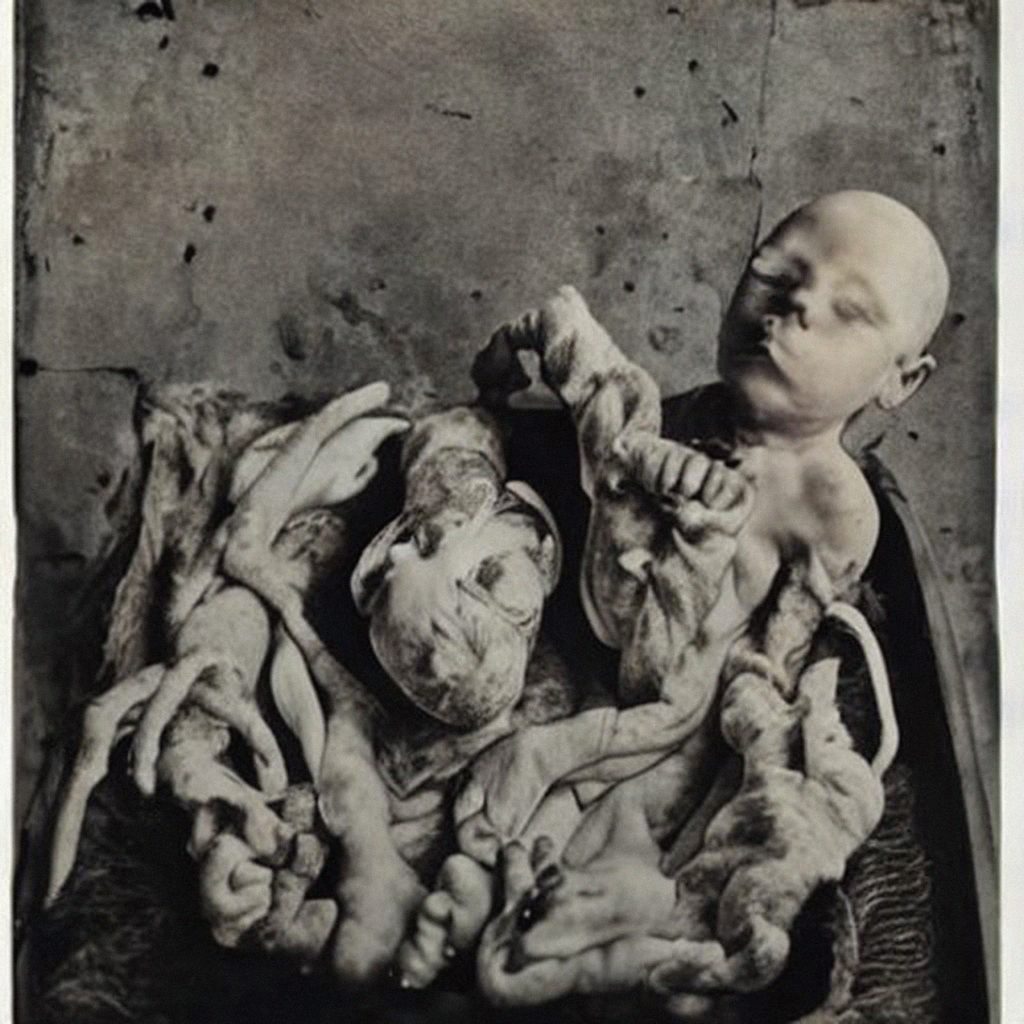








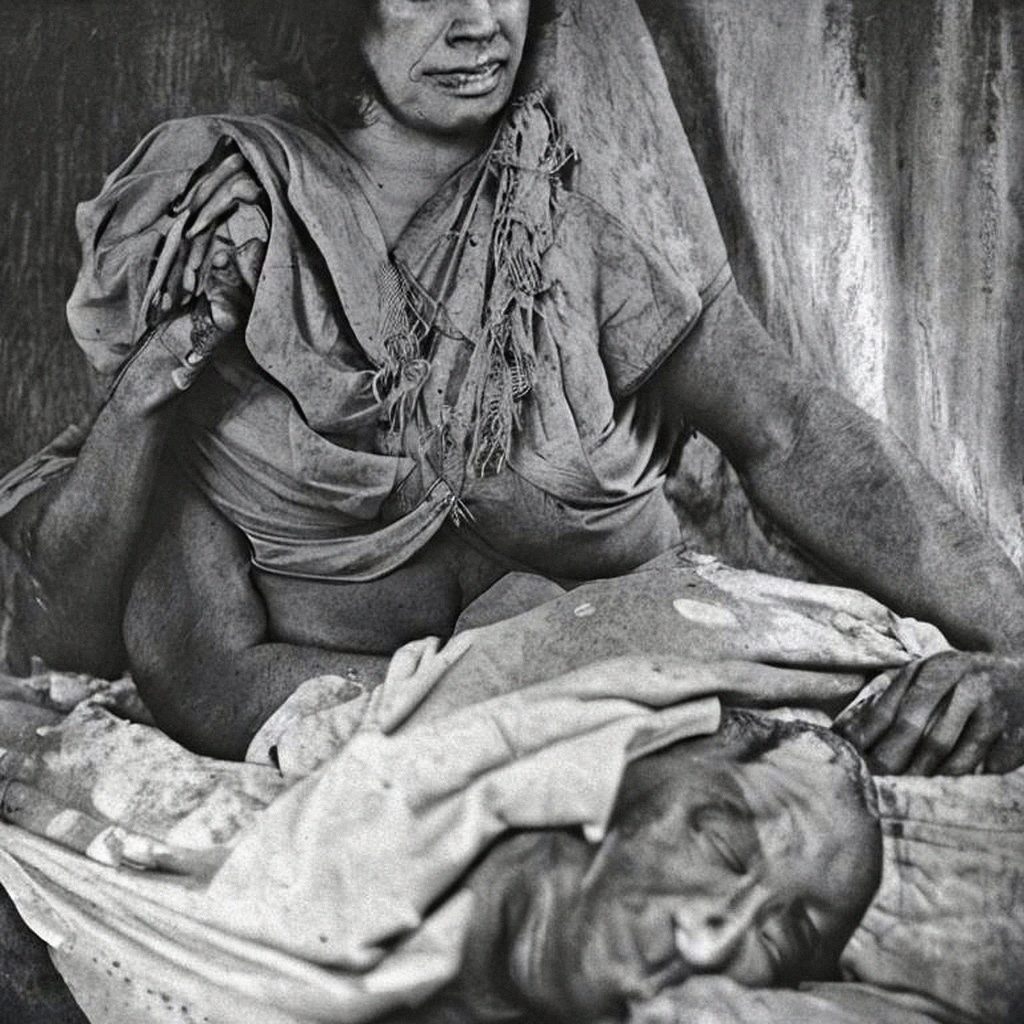



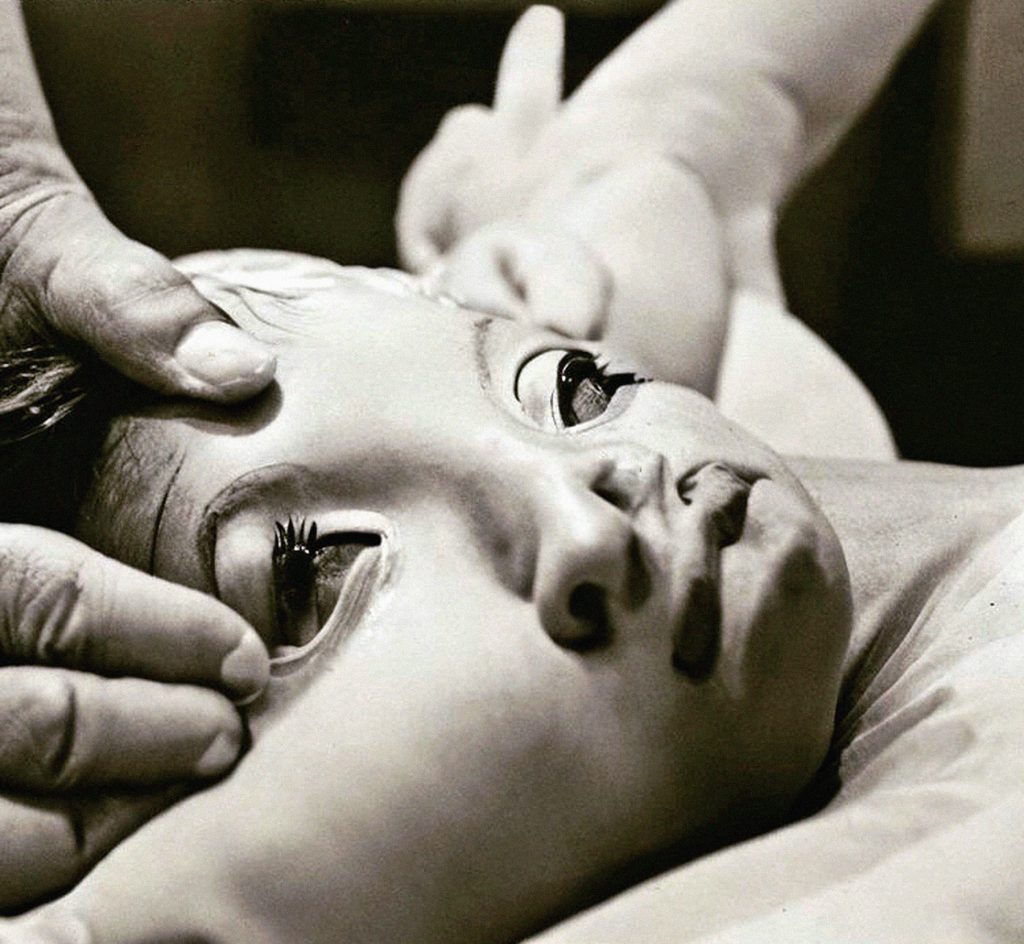








Exhibitions
March 1, 2025 – March 30, 2025. “Plasmatic Bodies.” RIVALS: Photography vs Promptography
presented by Photo Edition Berlin c/o Galerie Guelman und Unbekannt in Berlin, Germany for European Month of Photography. Curated by Boris Eldagsen in collaboration with Photo Edition Berlin and Guelman & Unknown.
July 27, 2024 – August 9, 2024. “Manifesto of the AI Avant-Garde.” Cartographies of Emotion presented by Plug-In Institute of Contemporary Art in Winnipeg, Manitoba. Curated by Irene Campolmi and Linda Lamignan.
Critical Discourse
DALL-E 2: The world’s seen nothing like it, but can AI spark a creative renaissance?
Leah Collins, “DALL-E 2: The world’s seen nothing like it, but can AI spark a creative renaissance?,” CBC (July15, 2022).
Think of anything. Seriously, anything. A turtle wearing a cowboy hat. Spider-Man blowing out birthday candles. Maybe a landscape painting of Algonquin Park, rendered in the style of Monet or Takashi Murakami.
If you have the words to describe your vision, no matter how strange — or banal, for that matter — it’s now possible to generate a picture in an instant, a file ready to download and share on your platform of choice.
It’s not magic, it’s AI. And in the last few months, the world’s become increasingly aware of systems that are capable of conjuring original images from a few simple keywords. The results are often startling — though not always because of their realism.
That’s especially true in the case of Craiyon (a tool previously known as DALL-E Mini), which is arguably the best known system of its sort. Free to use and available to all, the public swiftly adopted this open-source image-generator earlier in the year, and it’s become a meme-maker’s fantasy, spawning infinite threads of jokey one-upmanship.
Craiyon is trained on millions of images, a database it refers to when deciphering a user’s text-based request. But the pictures it delivers have never existed before. Every request for a portrait of Snoop Dogg eating a cheeseburger is wholly one-of-a-kind. The pictures lack photorealistic clarity, and there’s something to its grainy aesthetic, punctuated by spun-out faces, that suggests a nightmare seen through a car-wash window, but more powerful options are waiting in the wings.
On Thursday, Meta revealed it’s developing a text-to-image AI called Make-A-Scene, and earlier this year, Google revealed the existence of its own text-to-image generator (Imagen). Neither of those tools are currently available to the public, but there are other companies that have opened their projects to outside users.
Midjourney would be one example; there’s a waitlist to access its current test version, but admitted users can opt to join paid subscription tiers. Perks include friend invites and unlimited image requests.
But DALL-E 2 is the system that’s probably drawn the most attention so far. No relation to Craiyon/DALL-E Mini, it was developed by OpenAI, a San Francisco-based company whose other projects include AI capable of writing copy (GPT-3) and code (Copilot). DALL-E 2 is the latest iteration of a text-to-image tool that they first revealed in January 2021.
At that time, OpenAI’s system could produce a small image (256-by-256 pixels) in response to a text prompt. By April of this year, however, the AI (DALL-E 2) was capable of delivering files with four times that resolution, while offering users the option of “inpainting,” or further refining specific elements within their results: details including shadows, textures or whole objects.
Never mind the particulars of how any of this is possible (there are other resources out there that parse the science) — the results are astounding in their detail and slick enough for a glossy magazine cover. (Just check out the latest issue of Cosmopolitan, which features “the world’s first artificially intelligent magazine cover.”)
As such, DALL-E 2’s developers have taken a few steps to prevent users from dabbling in evil. Deepfake potential would seem to be a concern. Want a picture of a real person? That’s a no-no, though the technology is technically capable of doing it. And there are safeguards against images promoting violence, hate, pornography and other very bad things. Various tell-tale keywords have apparently been blocked; for example, a picture of a “shooting” would be a non-starter.
Access to the tool remains limited to a group of private beta testers, and though OpenAI says they want to add 1,000 new users each week, there are reportedly more than a million requests in their waitlist queue.
Still, even at this stage, the technology’s existence is raising plenty of questions, if not as infinite in quantity as the images DALL-E 2 can produce. Are creative industries facing obsolescence? When anyone can generate a professional-quality image with a few keystrokes, how will that impact graphic design, commercial illustration, stock photography — even modelling? What if the AI’s been trained to be racist or sexist? (Right now it sure seems to be.) Who owns the images that are spat out by one of these systems — the AI, the company that developed it or the human who typed “sofa made of meatball subs” and made it happen?
The future remains as murky as a Craiyon render, but for now, there’s at least one question we can begin to answer. If these tools have indeed been developed as a way to “empower people to express themselves creatively” — as the creators of DALL-E 2 purport — then what’s it like to actually use them? And what if your job is all about creativity? How are artists using AI right now?
CBC Arts reached out to a few Canadian artists who’ve been dabbling with AI systems, including DALL-E 2, whose research program currently includes more than 3,000 artists and creatives. How do they see this technology changing the way they work?
Here are some of the early thoughts they had to share.
[…]
“It feels like I could actually make the type of images I want to make.”
Clint Enns
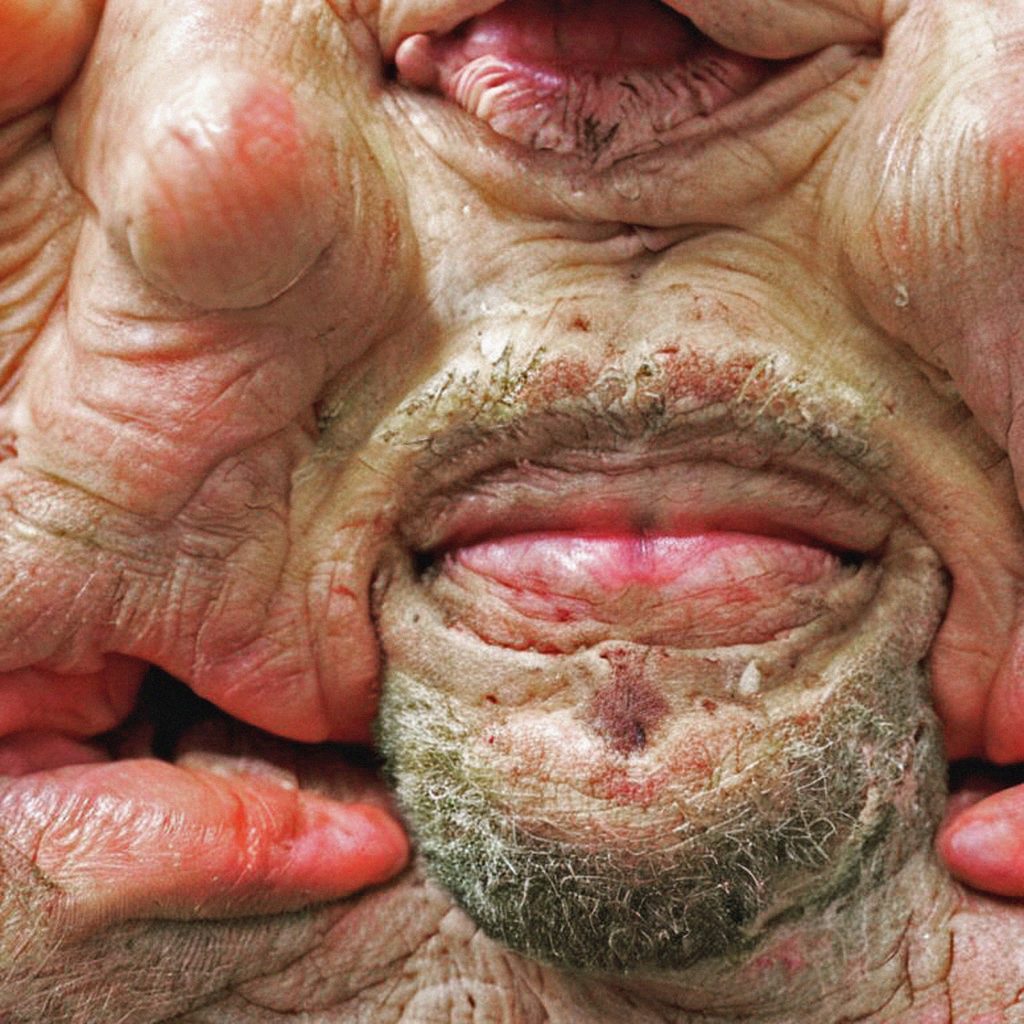
While he waits for DALL-E 2 access, Clint Enns is busy investigating whatever AI systems are available to him, but two free and open-source tools have been his go-to options so far: Craiyon and Disco Diffusion. Originally from Winnipeg, Enns is the artist behind Internet Vernacular, an ongoing found-photography project that traces the evolution of visual communication throughout the digital age. Its last public exhibition focused on the year 2004, and the birth of the shareable “social photo.” It’s tempting to think 2022, the dawn of DALL-E 2, will feature in a future chapter of the series.
First impressions?
Everybody’s doing it right now, which is kind of fun. I think it’s really captured the imagination of a lot of artists.
Although machine learning has been around for a little while it always felt like the results were simply in the realm of science fiction or fantasy art. Kind of cheesy. But it feels like something’s broke. It now feels like there’s real potential in the technology. It feels like I could actually make the type of images I want to make.
The images look flawed. I think that’s what was magical about them for me — that they look glitchy and broken down. Like DALL-E Mini: all of the faces are just melting, right?
How are you using AI?
I’m still using DALL-E Mini. It’s really informative to see what other artists are feeding into the machine as prompts. You can really learn about an artist’s practice just by seeing what prompts they are using, similar to the way that the machine is learning from us. The prompts they are using usually reflect what they are trying to make in their “regular” practices.
I was trying to see how the machine would interpret my prompts, in particular, where it failed. I like to provide it with what I consider impossible tasks for things that I think would be funny, or things that are self-referential. Like, “an AI-generated face.” You put in that prompt and see what it thinks an AI-generated face looks like.

When I start to understand this technology a little better, I’m hoping to put out a chapbook where I think through the images. Like, thinking about what art is in an era where of machine generated art. I already have a line for it: something like, “I’m just waiting for the machine to become sentient enough to sue artists using its results for copyright infringement.”
Why should artists have access to AI tools?
What I’m trying to do is explore where technologies break down or fail. I’ve been doing this throughout my practice — like by making glitch art. I think artists are really good at finding those failures and exploiting them.
You can generate perfect landscapes with this technology, but you can only see so many of these perfect landscapes. It’s where these technologies start to break down that they open up. I really think that’s the artist’s job in all of this. To reflect on the technologies.
How is AI going to change what you do?
I think this technology raises a lot of challenges to the artist. Can a machine do it better than us? Whenever a new technology comes up, it always poses a challenge to the artist. Think about photography, right? Why paint when you can just take a photo of something? Artists always find a way of both using the technology in innovative ways and responding to it.
It feels really exciting, like the birth of a new type of computing? It’s like when I was a kid and I got my first computer and I could do things that I couldn’t do before. It feels like this tool is going to allow that. It has lots of potential.
These conversations have been edited and condensed.